This is a copy of a blog post I wrote originally posted on InfluxData.com
As part of the new v1.22.0 Telegraf release, Telegraf is happy to announce the availability of a faster, more memory-efficient implementation of the Line Protocol Parser. Users who make heavy use of line protocol and are parsing huge amounts of data will greatly benefit. This new parser is already in production across InfluxDB Cloud as well.
While this new parser is not the default setting, users can enable the new parser with a single configuration option to take advantage of these improvements:
Influx Parser format Link to heading
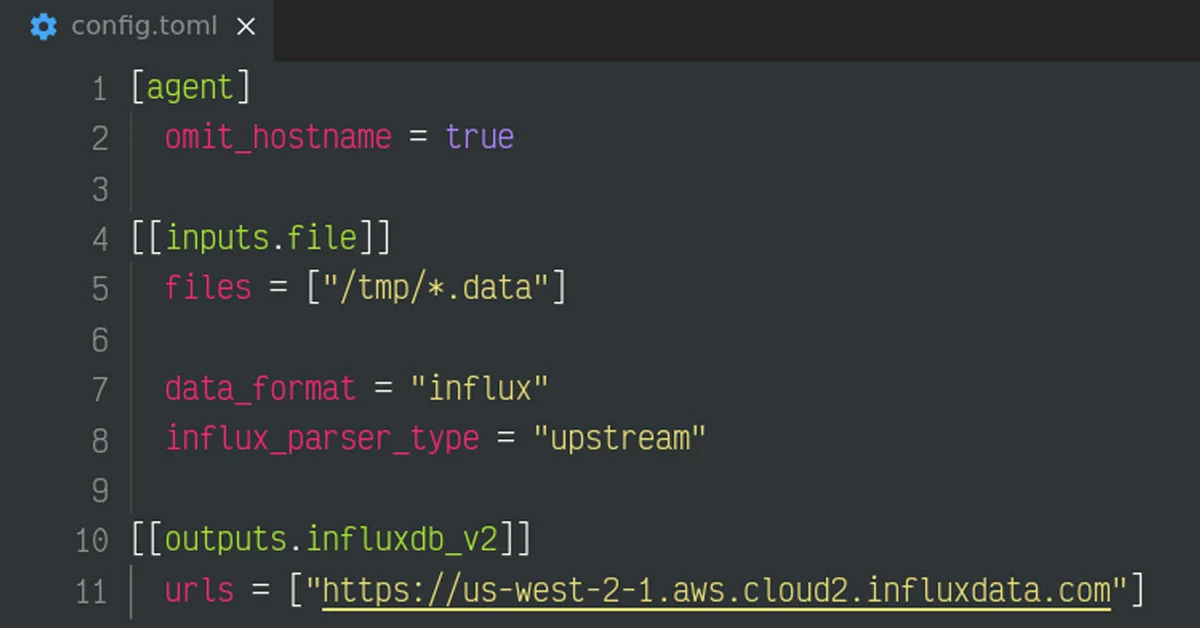
To enable the use of the new parser while using the influx data format, set the parser type to “upstream”:
| |
The “upstream” value will enable the use of the new faster more memory efficient parser, while “internal” (which is the default setting) will continue to use the existing parser. This setting allows users to opt-in to the new parser and allows us to collect more confidence in ensuring the stability of existing configurations.
If the option is omitted it will use the default, which is currently “internal”. In a future release, Telegraf will switch the default parser to use the new parser.
Here is a full example, while using the file input plugin:
| |
InfluxDB Listener Link to heading
Users of the influxdb_listener or influxdbv2_listener plugins can also take advantage of the new parser by setting the parser_type option to “upstream”:
| |
If the option is omitted, it will default to “internal”. In a future release, this value will also switch to using the new parser.
Try it out Link to heading
Whether you are parsing Influx line protocol or not, head over to the GitHub release page for Telegraf, and let Telegraf help you collect metrics today!